之前,我們都在影像、語言等基礎應用上打轉,這次我們要來探討一個可應用在企業運作上的實例,銷售預測主要是希望藉由過去的銷售記錄預測下一個週期的銷售量,在統計上,我們會使用簡單迴歸,乃至複雜的『時間序列分析』(Time Series Analysis)來預測銷售趨勢,因為,當期的銷售量通常會與前期的銷售量有緊密的關係,除非公司發生重大事件,否則,應該會循著規律變化。還記得嗎? 在『自然語言處理』時,我們會使用LSTM考慮上下文的關係,這個模型恰好與前面講的銷售量預測不謀而合,所以,本篇就以 LSTM 模型來預測銷售量。
銷售量預測的樣態很多種,包括營收、利潤、來客數、遊園人數、銷售產品數/金額、...等等,都屬於同一範疇,本篇會以航空公司的每月乘客人數為例,使用 LSTM 模型預測下個月的乘客數。
簡單迴歸(Regression) 公式 y=ax+b,是基於 y(i) 與 y(j) 是相互獨立,沒有任何關聯,但在銷售量的表現上,這個假設並不合理,公司銷售業績通常不會暴漲暴跌,而是『逐步』上升或下跌,也就是與前期的表現有緊密的關聯,另外,大部分的公司也會有淡、旺季,即所謂的『季節效應』(Seasonal Effect),因此,使用更複雜的『時間序列分析』(Time Series Analysis)預測會更貼近事實,時間序列分析的模型因應問題的型態不同也有很多種,我們以ARIMA(Autoregressive Integrated Moving Average)為例,做簡單的說明,如果你對以下的說明很頭痛,可跳過,直接看 Neural Network 怎麼作。
參考Wiki的簡介,ARIMA 是 ARMA 的擴充模型,而 ARMA 就等於 AR + MA,AR 談的就是與前期的關係,有一重要的參數 p,代表期數,就是假設當期與前面p期有關係,MA 是移動平均數(Moving Average)就是避免異常值影響過大,故利用前幾期的平均數來代表當期量,所以,也有一個重要的參數 q,代表計算移動平均的期數,另外,ARIMA 多一個參數 d,稱為差分階數,是要使時間序列維持『穩態』(stationarity),所以,總共有三個參數 p、q、d,相關的理論是一門學科,筆者只能點到為止。
至於p、q如何決定是多少呢? 可利用『自我相關函數』(Autocorrelation Function,ACF)或『偏自我相關函數』(Partial Autocorrelation Function, PACF)來協助判斷p及q值,至於 d 值的判斷可參考『Identifying the order of differencing in an ARIMA model』,經過反覆的數據觀察、分析與實驗,才可以得到較接近事實的預測模型。
綜合以上說明,我們可以了解以統計模型預測銷售量,是須具備一定的知識以及行業別知識(Domain Know How),才能建立較正確的預測模型,接下來,我們來看看 Neural Network 的方法。
相關的實作可使用 StatsModels 套件,它支援『時間序列分析』與繪圖。
以下說明及實作主要參考『Time Series Prediction with LSTM Recurrent Neural Networks in Python with Keras』,資料集採用『航空公司每月乘客人數』,可至這裡下載,我們利用以下程式畫出乘客人數的折線圖:
import pandas
import matplotlib.pyplot as plt
dataset = pandas.read_csv('international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)
plt.plot(dataset)
plt.show()
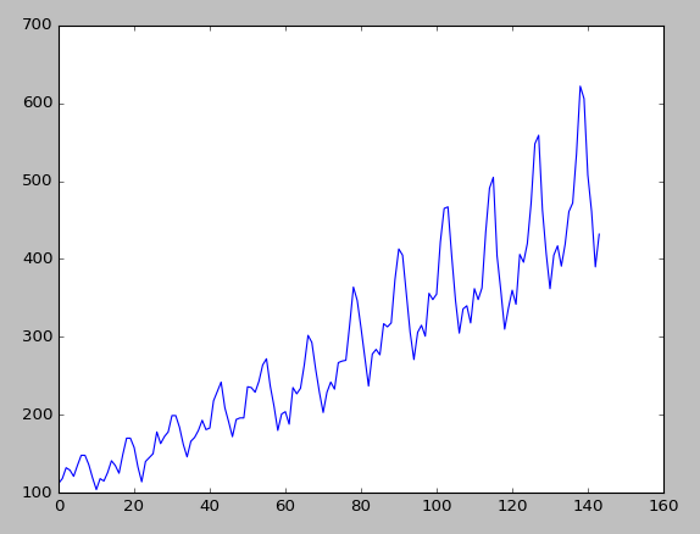
圖. 航空公司每月乘客人數
我們可以觀察到數據有一定的趨勢與波動性,暑假(7~9月)乘客人數比較多,表示有季節效應,我們可以用ACF或PACF確認一下:
import numpy as np
from scipy import stats
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
# 畫出 ACF 12 期的效應
sm.graphics.tsa.plot_acf(dataset, lags=12)
plt.show()
# 畫出 PACF 12 期的效應
sm.graphics.tsa.plot_pacf(dataset, lags=12)
plt.show()
** 注意,StatsModels 套件,必須以以下指令安裝,用 pip install 會有錯 **
conda install -c conda-forge statsmodels
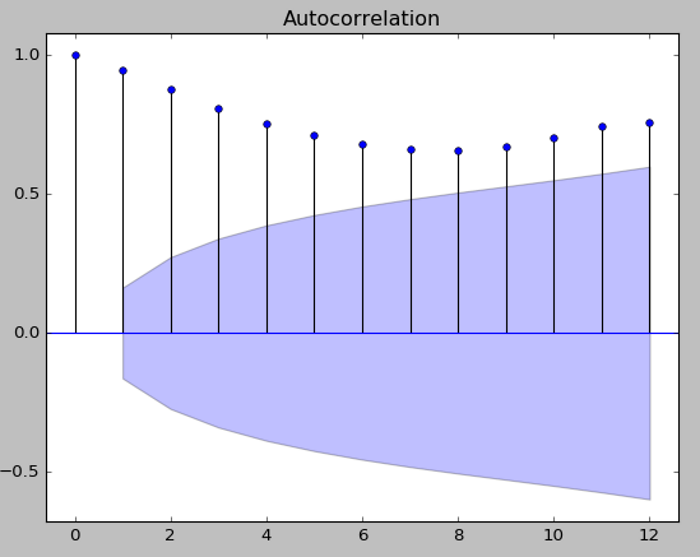
圖. ACF 12 期的效應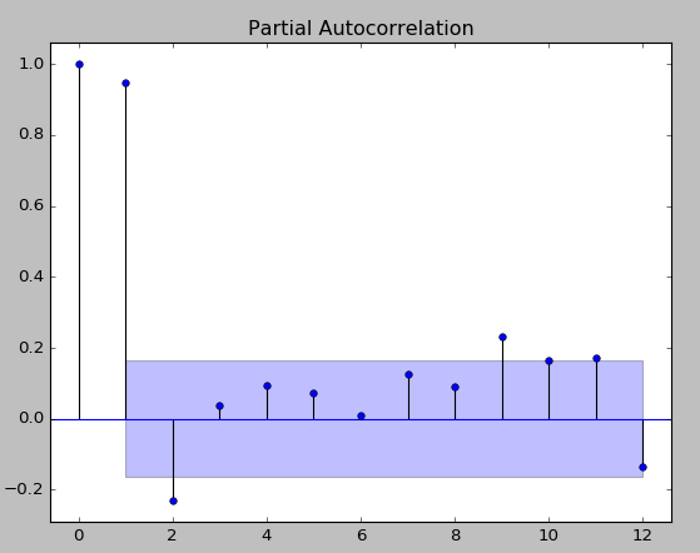
圖. PACF 12 期的效應
接著,我們就以 LSTM 模型實作,程式碼來自『Time Series Prediction with LSTM Recurrent Neural Networks in Python with Keras』,我加了一些註解,也可至這裡下載,範例在 TimeSeries 資料夾,如下:
# LSTM for international airline passengers problem with regression framing
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
# 產生 (X, Y) 資料集, Y 是下一期的乘客數
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# 載入訓練資料
dataframe = read_csv('international-airline-passengers.csv', usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
dataset = dataset.astype('float32')
# 正規化(normalize) 資料,使資料值介於[0, 1]
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 2/3 資料為訓練資料, 1/3 資料為測試資料
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# 產生 (X, Y) 資料集, Y 是下一期的乘客數(reshape into X=t and Y=t+1)
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# 建立及訓練 LSTM 模型
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 預測
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 回復預測資料值為原始數據的規模
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# calculate 均方根誤差(root mean squared error)
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# 畫訓練資料趨勢圖
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# 畫測試資料趨勢圖
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# 畫原始資料趨勢圖
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
將下載的資料檔international-airline-passengers.csv與程式SimpleLSTM.py放在同一目錄,在DOS內執行以下指令:
python SimpleLSTM.py
執行結果如下: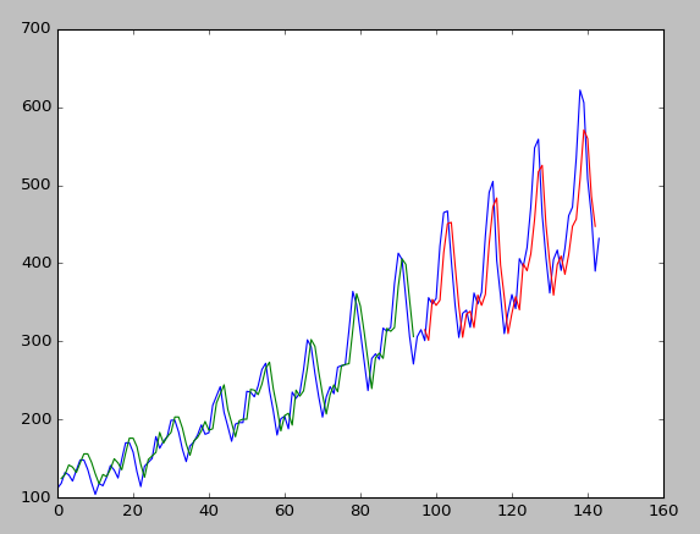
圖. LSTM 預測結果,藍線為實際值,綠線為訓練結果,紅色為測試結果
程式不複雜,可參閱中文註解,處理流程如下:
可以看到很神奇的現象,我們沒有特別處理季節效應,但 LSTM 經過 100 輪的訓練後,幫我們考慮到了,模型只使用前期資料為X變數。另外,我們也可以使用多期的資料作為X變數,或者,針對季節效應對 LSTM 作『記憶重置』(reset state)、以期數(Time Steps)當input處理、...等等的方法,針對問題特性,多實驗看看,也許會有意想不到的效果。
其實,我們周遭不乏其他的例子可以實驗,例如雨量、氣候、上市公司營收、股價預測、房價預測...等等,都屬於時間序列,尤其,政府目前提供許多 Open Data,取得資料並不困難,重要的是,我們怎麼看待資料,是否有創新的想法吧。
請問為什麼加了skipfooter之後跑出來的結果會比較好?
還有ACF、PACF的圖要怎麼看,可以麻煩您解釋一下嗎?
有爬了一些文但還是不太懂ARIMA的部分
ACF/PACF是顯示當期與落後期數的相關程度,從上圖PACF看,當期(左邊第一條)與上期(左邊第二條)最密切,故使用上一期預測當期。
所以假設PACF的圖中左邊第三條比起左邊第二條的數值和當期最密切的話,全部的look_back都要改成=2,還是只有create_dataset內的要變更?
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
上面第一行改成2即可。
好的,那這方面沒什麼問題了,不過關於skipfooter的部分,請問有辦法能解釋這樣的變化嗎?
skipfooter 是因為最後三列不是資料,故跳掉而已。
那我了解了,原來是因為我是用在原文中的資料庫,所以一直不解為何要使用skipfooter,感謝您的回覆。
您好,根據您提供的程式碼我有大概了解了八成,但一直還有個疑問,在最後只有得到訓練集和測試集的計算結果,那如果我要把預測的結果向後延伸該怎麼做?意思就是原始資料集最後是1960/12,但我想得到1961/1的數值。
因為依照我目前的理解認為,到目前為止只是畫出了一條和原始數據相近的線,並沒有做到預測未來的部分。
還是其實是我有哪部分理解錯誤?
再麻煩您解惑,謝謝!
# 最後一筆的乘客數當作X,預測下個月的乘客數
last_row = scaler.transform(testY[0][-1].reshape((-1, 1)))
last_row = numpy.reshape(last_row, (last_row.shape[0], 1, last_row.shape[1]))
testPredict2 = model.predict(last_row)
#print(testPredict2)
scaler.inverse_transform(testPredict2)
好的 感謝您的回應,文章對我非常有幫助
您好請問若我要預測接下來好幾期的數值,例如接下來12個月的乘客數量,有辦法嗎?
LSTM 一次只能預測一期,我發現一個很棒的套件 -- FB Prophet,可一次預測很多期,有興趣可以研究一下。
近期有空的話,我會分享一下閱讀心得。
您好,請問上面您所提供的資料集連結-->"資料集採用『航空公司每月乘客人數』",要如何下載呢??
我點進去之後會進入,商用數據分析網站,選試用登錄進去後重新使用您所提供的連結,也找不到
能分享一下您當時怎麼找到這個資料集的嗎??
謝謝你的回覆 很有幫助
您好,近期我剛接觸LSTM,關於LSTM的一些參數還是理解不懂
想請問LSTM是只接受三維數組的資料嗎?
所以如果我有一個二維陣列的資料的話要先reshape成三維再丟入LSTM
我看到您上面reshape的部分是在time_steps的位置加入1
請問這個用意是什麼意思呢?
另外還想請問LSTM中的input_shape()中的參數含意是代表什麼意思?
因為我看到有些例子他們會在input_shape()裡面放入三個參數,有些只會放兩個
所以想請教您這個問題,不好意思問題有點多。
LSTM是只接受三維數組的資料嗎?
==> 是,請參閱 https://keras.io/api/layers/recurrent_layers/lstm/
inputs: A 3D tensor with shape [batch, timesteps, feature].
time_steps的位置加入1
==> 每一期資料只跟前"一"期有關
input_shape
==> 設定模型輸入的維度大小,注意,不含第一維批量。
相關規格可參考 https://keras.io ,比較精準。
所以time_steps的位置不一定每一次都是直接加入1嗎?
請問input_shape中 "注意,不含第一維批量" 這邊是指
如果輸入的參數是兩個的話就不包含Batch-size嗎?
還想請教一下[Batch-size, TimeSteps, Features]
分別指的是要訓練的資料的[總筆數, 時間維度, 特徵值]嗎?
全部都對喔,厲害。
那想請教一下
為什麼input_shape()裡面不需要放入Batch-size的參數?
是因為我們在後面model.fit的時侯會設定Batch-size嗎?
因為 Batch-size 是會變動的,與模型結構本身無關。
好的,了解,謝謝您耐心地回覆。
如果之後還有其他問題的話,可以寄站內簡訊詢問您嗎?
OK.
您好 想請教
我如果只想用測試集的前五個值做預測呢?
我試過以下這樣子似乎沒辦法...
for i in range(0,len(testX),step=5):
testPredict = model.predict(testX[i:i+step])
因為我想要預測五個值[0:5]後再訓練,在預測五個值[6:10]該怎麼做呢?
要一次預測多期的目標,稱之為 Multi-Step LSTM Time Series Forecasting,請參閱這一篇說明:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
想請教 如果測試集為一期(裏頭有200個樣本)
我想先取5個做預測,然後再訓練模型在預測5個值,直到200個樣本結束這樣可以嗎?
這樣好像是單期的問題
也可以,只是每預測一期,就需重新訓練,預測速度過慢。
不好意思,想請教一下具體該怎麼做呢?
以下是我嘗試過的方式....
def create_dataset (X, look_back = 1):
Xs, ys = [], []
for i in range(len(X)-look_back):
v = X[i:i+look_back]
Xs.append(v)
ys.append(X[i+look_back])
#print('Xs: ', Xs)
#print('ys: ', ys)
return np.array(Xs), np.array(ys)
for i in range(0,len(X_test),5):
X_test1 = X_test[i:i+5]
a = model.predict(X_test1, batch_size = batch_size)
#print('a :',a)
#print('a :',a.shape)
prediction = np.array(a)
prediction = scaler.inverse_transform(prediction)
X_a, y_a = create_dataset(a,5)
#print('X_a :',X_a.shape)
#print('y_a :',y_a.shape)
new_model = model
if X_a.shape[0] >= 5: #樣本數大於5 訓練
new_history_lstm = new_model.fit(X_a, y_a, epochs = 1, validation_split = 0.2,
batch_size = batch_size, shuffle = False,callbacks = [early_stop])
else:
break
每預測一筆就append到資料集中,再重新訓練/預測即可。
您好,我剛接觸python和lstm,想請問一個問題,文章中的訓練資料設0.67,是將此data前面2/3筆做訓練資料,想請問我想將此data隨機2/3筆做訓練資料,該如何進行修改比較好,謝謝您
https://i.imgur.com/Mx7sLFl.png
雖然我不是很懂
但我想 你可以先random.seed()後再做0.67切割呢
前面2/3筆做訓練資料,是要以過去預測未來,若採隨機分割,就有可能變成以未來預測過去。
您好~剛接觸LSTM的小萌新想請教一下
就我的理解,這個範例是不是 one-to-one 呢?
如果我想以上述資料集一年的資料 來預測下一年的資料 來實現many-to-many
EX.input:[1960年1~12月各月的人數] -> 預測output:[1961年1~12月各月的人數]
請問有辦法實現嗎?
感謝您~
可以參考這一篇:
https://medium.com/neuronio/predicting-stock-prices-with-lstm-349f5a0974d4
設定 foward_days 為預測筆數。
model = Sequential()
model.add(LSTM(NUM_NEURONS_FirstLayer,input_shape=(look_back,1), return_sequences=True))
model.add(LSTM(NUM_NEURONS_SecondLayer,input_shape=(NUM_NEURONS_FirstLayer,1)))
model.add(Dense(foward_days))
您好~我是剛接觸LSTM的新手,在參數設定上有些不確定的疑問想請教您。
我嘗試把look_back的值修改成與我目前手中資料符合的period = 6
目前的情況我在 reshape 的部分,trainX.shape[1] = 6
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
3個數值應該是 [samples, time steps, features]
而根據前面其他邦友的提問, time_steps 需要根據不同的期數而修改,
所以在我的資料中, time_steps是該修改為6嗎?
若是的話,這樣reshape出來的值會超過data原本的size,請問是我哪裡有做錯嗎?
p.s. 我的目標是透過前六期的資料來預測下一期的數值
感謝您~~
透過前六期的資料來預測下一期的數值 ==> 只需修改第36行。
look_back = 6
瞭解了~您的文章對我的幫助很大 十分感謝!
您好,我是剛接觸PYTHON與LSTM的新手。
看完文章後明白這個實作是以X去預測下一期的X,
若我想以X1,X2,X3,...,Xn來預測下一期的X1,
該如何修改會比較好?
謝謝您
透過前n期的資料來預測下一期的數值 ==> 只需修改第36行。
look_back = n
您好,我想您誤會我的意思了。
我是想要以多個input,最後產出一個output的形式,
謝謝~
可以參考這一篇:
https://stackoverflow.com/questions/42532386/how-to-work-with-multiple-inputs-for-lstm-in-keras
也可以使用 Functional API,多個 input layer, 後接 dense:
https://keras.io/guides/functional_api/
或者使用 Prophet 套件
https://facebook.github.io/prophet/docs/seasonality,_holiday_effects,_and_regressors.html#additional-regressors
好的謝謝~
我試試看
您好,我是剛接觸LSTM的新手。
我與樓上某人依樣有相似的問題,再勞煩您解答了。
我在網路上找到關於LSTM不少的實作code,但幾乎都是將資料分隔成train及test的資料。
但使用test的資料預測與test同一時間的資料真的能算得上預測嗎
所謂的預測不是應該是從無到有的狀態嗎?
我目前使用了10000多筆資料進行模型的訓練,並以120筆資料為一個時間序列去預測下一筆資料
我利用迴圈的方式將train的最後一組120筆的資料取出得到了第121筆資料,再將原120筆資料的第一筆資料去除,將第121筆放置最後,接著在去預測下一筆資料(122筆)
但實際上的效果是非常的差的,且持續到120筆以上後會變成一個規律的走向,並無參考性可言。
想詢問這部分我可能是哪邊有理解錯誤或設定錯誤的東西嗎
感謝您
使用test的資料預測與test同一時間的資料真的能算得上預測嗎?
==> test data 未參與訓練,故可視為新資料的預測,test data 通常是評估模型的準確度,模型準確度可接受後,再利用模型預測未來。
本範例主要是解釋如何利用LSTM預測時間序列,只以AR模型實作,事實上還有許多可擴充的地方,可參考 Prophet說明。
實際上的效果是非常的差。
==> 這部分網路上有許多的討論,可參閱Predicting stock prices with LSTM,拙著第12章也有中文說明。
關於時間序列的內容非常多,希望未來有專書詳細探討。
感謝回覆
關於第一點我想再提出我的想法
因為所謂的未來是沒有資料的,僅能使用預測
而目前來說是拿過去的某個時間點當作當下,拿已發生過的事實(未來)去做驗證後得到結果再去評估是否良好也能理解
但實際上我自己做出來的結果是前者驗證後結果非常好,但實際上我將它改成我上述所說的真實地去往下預測,而沒有給他資料再去產生則會很慘
對此想請教有沒有什麼更好的方法這樣
未來是沒有資料的,僅能使用預測
==> 應該會有特徵(X),才能預測Y,時間序列AR(1)的X就是前一期的Y。
您說的沒有錯
但如果預測的時間越來越長的話,例如我的作法是一次預測一筆,再將預測的資料丟回再進行預測,到最後就會變成用預測進行預測的狀態,若將概念轉成影片生成的方式的話是否能解決傳統LSTM無法長期預測的問題呢?
試試看,也許可以寫一篇論文喔。
老師您好,想請較3個問題。
1.如果要放激活函數(ex.tanh、sigmoid、relu等等),在哪條程式碼插入會比較好呢?若插入的程式碼是否如下:
activation_fn = tf.nn.leaky_relu
2.檢測模型的好壞,會建議MAE還是RMSE呢?
3.本學生有參考您的程式碼(謝謝您),想請問我最後想要做此模型的精準度(%),要如何呈現?
謝謝老師您的幫忙。
老師您好,想請教您一個問題
我想利用LSTM進行預測,只是不知道可不可行
我的問題是我想利用溫度感測器收集到的資料做異常發生時間間隔的預測
假設超出我訂定溫度的資料視為異常資料,我會有這些異常資料發生時間的歷史資料
但這些資料的時間間隔是不規則的,目前我的作法是用上一筆時間跟下一筆時間的時間間隔(分鐘)去做預測
所以我的資料就只有一個欄位就是每筆異常的時間間隔
如果我想利用前幾次的時間間隔去預測未來下一次的時間間隔,請問這用LSTM是有辦法預測的嗎
謝謝老師~
你已知異常資料的時間間隔是不規則的,但是你又想預測下一次異常的時間間隔,這個立論有點矛盾,建議先利用時間序列模型,例如,下列網址進行建模,看看 Holiday 效應與異常資料是否相符,再觀察異常資料發生是否有規則性,再決定是否利用演算法預測下一次異常的發生點。
偵測異常也可google 【anomaly detection for time series】,另外可靠度工程也有提到MTTF(Mean Time To failures),都可以參照。
老師您好,不好意思我沒有看到您貼的網址,我可以用站內簡訊跟您詢問嗎,謝謝!!
忘了貼網址:
新增一個欄位:是否為異常點。將此欄位當格外的X變數(regressor)。
https://facebook.github.io/prophet/docs/seasonality,_holiday_effects,_and_regressors.html#prior-scale-for-holidays-and-seasonality
觀察模型是否MSE較小,異常資料發生是否有規則性,再進一步處理。
老師非常感謝您~~~ 我研究看看
如果有問題可以在站內簡訊問您嗎
ok
您好我想請問一下,最後的結果的藍色部分是原始y值所繪出來的,我的理解有誤嗎?如果是y值的話x值以什麼為依據,再麻煩您賜教
藍線為實際值,綠線為訓練結果,紅色為測試結果。
X是日期。
所以藍色是以銷售量來畫的,這樣理解對嗎
是。



{kind=link}